Scraping with Tor
by Anas El Mhamdi
At Quable, we run a lot of automated jobs in the background. One of the most interesting marketing campaigns we’ve been running are job boards as sources of marketing signals and business intelligence.
Job postings reveal valuable signals about company growth and market needs. For instance, if a company is hiring multiple sales positions, it suggests rapid expansion and potential demand for tools and services.
The Motive
Quable develops PIM/DAM software for product information management. We help clients centralize and manage their product catalogs, making it easier to distribute across multiple channels.
The strategy involved identifying companies posting job openings that mention “omnichannel” in their materials. These companies are likely experiencing growth and need organizational tools to manage their product information across multiple platforms—exactly what Quable provides.
The idea here is to find out which companies are looking for manpower and strike a conversation with their CTO/CMO to explore if Quable’s solutions could help them scale their operations.
I initially used Phantombuster to scrape LinkedIn job listings. While it provided company names and LinkedIn URLs, it lacked the actual job descriptions themselves—the most valuable part containing keywords like “omnichannel.” This limitation prompted a custom scraping solution.
Scraping the LinkedIn Job Offers
Using BeautifulSoup and basic curl requests proved effective initially. I could extract the job offer content without issues.
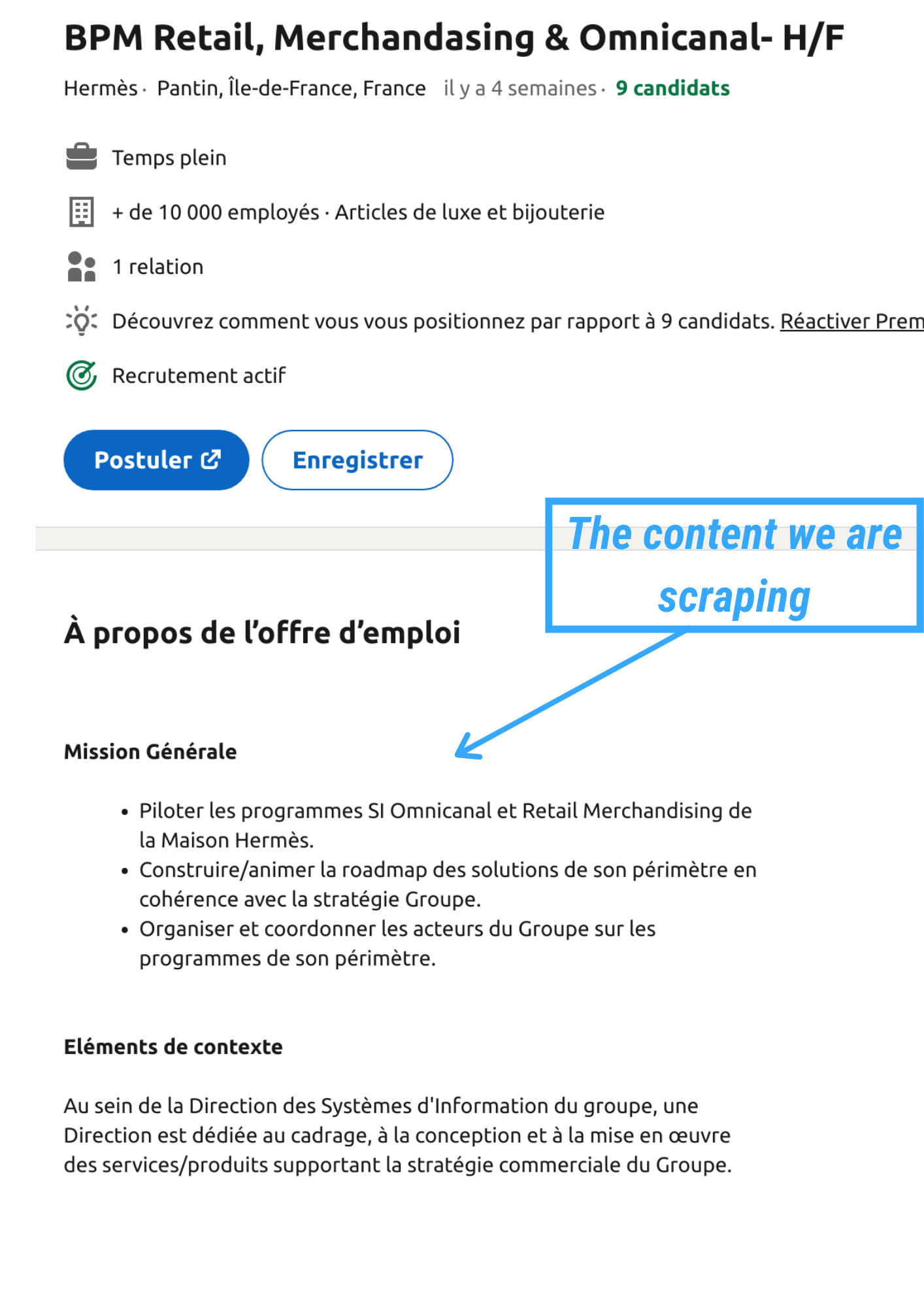
However, after approximately 20 requests, LinkedIn detected the activity and was onto my IP address.

The connection was terminated after 42 total requests, showing clear signs of IP-based blocking.

TOR? Deep Web?
Tor is a privacy-first tool/network, which is why it has a bad mainstream reputation: anything using privacy as a core feature is bound to be used by criminals and those seeking anonymity for legitimate or illegitimate purposes.
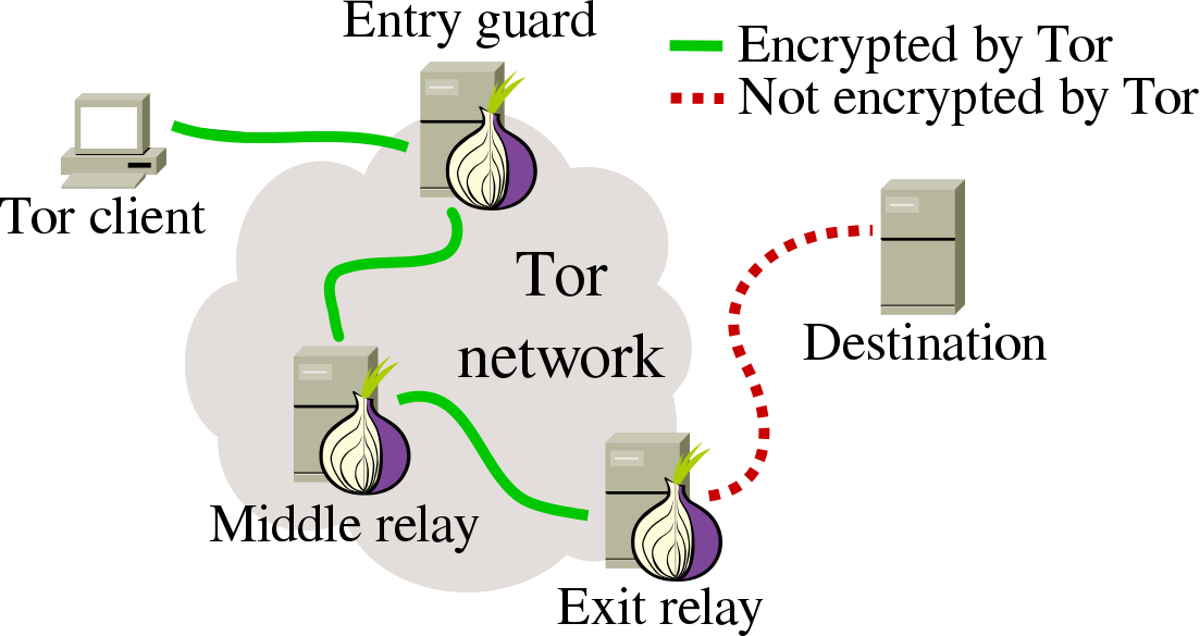
The technology enables near-untraceable connections by routing traffic through multiple relay nodes, making it extremely difficult to trace the original source. While it doesn’t offer premium performance, Tor serves as a viable proxy alternative with modest performance trade-offs that are perfectly suitable for small scraping projects.
Quick Tor Setup and Usage
For Windows users: There are comprehensive tutorials available online for setting up Tor on Windows systems.
Linux/Debian installation:
sudo apt-get install torAfter installation, edit the /etc/tor/torrc configuration file with the following settings:
SOCKSPort 9050
HashedControlPassword YOUR_PASSWORD
CookieAuthentication 1Restart the Tor service to apply the changes:
sudo /etc/init.d/tor restartInstall the Python TorRequest wrapper to easily integrate Tor into your Python scripts:
pip install torrequestActually Using Tor
The implementation is straightforward. I wrapped my existing scraping logic by replacing requests.get with tr.get (TorRequest). The key innovation was implementing the reset_identity() function to rotate IP addresses whenever LinkedIn rejected requests.
from torrequest import TorRequest
# Initialize Tor request handler
tr = TorRequest()
# Use tr.get instead of requests.get
response = tr.get(url)
# Reset identity when blocked
tr.reset_identity()This approach successfully completed scraping all 150+ target job listings without further interruptions.

The progress bar shows smooth execution without connection errors.
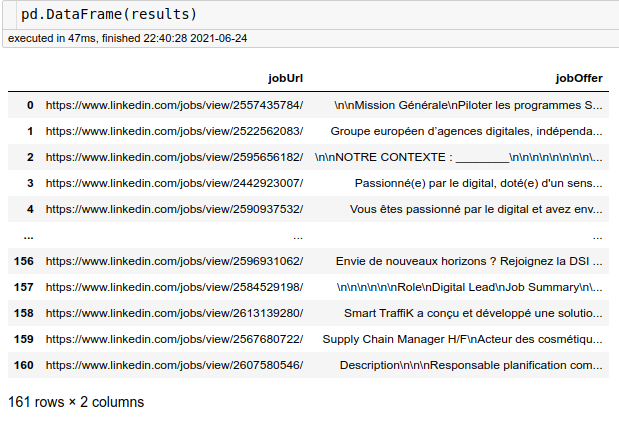
All job offers were successfully retrieved with complete content, allowing us to search for relevant keywords and identify potential leads.
Conclusion
Tor is a nice tool to work with when you don’t want to go ballistic on your scraping stack. While it’s slower than dedicated residential proxies or sophisticated browser automation frameworks, it effectively handles small-scale projects without requiring expensive infrastructure.
For modest scraping operations like this one—collecting a few hundred job postings—Tor provides an excellent balance between anonymity, cost (free), and ease of implementation. It’s not meant for large-scale industrial scraping, but for targeted data collection, it works remarkably well.